Fast & Furious Tensor Parallelism: GPU Heist Gone Wrong
Splitting a model across 4 H200 GPUs was expected to 4x throughput, but instead resulted in 2.8x worse latency and 35% lower throughput. Without NVLink, tensor parallelism causes more communication overhead than speedup, so sometimes 1 GPU outperforms 4

After settling on a model (Qwen3-30B), I thought the next logical step was optimizing for throughput. The model fit on a single H200 GPU, but could I split it across 4 GPUs and serve 4x more requests?
Spoiler: No. Tensor parallelism made everything slower. This is a deep dive into why adding more GPUs sometimes makes your inference worse, not better.
The Promise of Tensor Parallelism
Tensor parallelism splits a model across multiple GPUs by partitioning the weight tensors. Each GPU holds a slice of the model, and they work together to produce outputs.
The idea is compelling:
- Distribute the model's memory footprint across GPUs
- Parallelize matrix multiplications across devices
- Theoretically, 4x throughput with 4 GPUs
For training, this works beautifully. But for inference? The math is different.
What Are Tensors, Anyway?
Before diving into tensor parallelism I want to explain what tensors actually are.
A tensor is just a multi-dimensional array of numbers.
- A scalar is a 0-dimensional tensor:
5 - A vector is a 1-dimensional tensor:
[1, 2, 3, 4] - A matrix is a 2-dimensional tensor:
[[1, 2], [3, 4]] - A 3D tensor:
[[[1, 2], [3, 4]], [[5, 6], [7, 8]]]
In a transformer model, weights are stored as tensors of various dimensions:
Query weight matrix: [hidden_size, hidden_size]
Example: [4096, 4096] = 16.7 million parameters
Attention multi-head weights: [num_heads, hidden_size, head_dim]
Example: [32, 4096, 128] = 16.7 million parameters
Feed-forward weights: [hidden_size, intermediate_size]
Example: [4096, 11008] = 45 million parameters
For Qwen3-30B, there are ~60 layers, each with multiple weight matrices. The total: 30 billion parameters.
When we talk about "tensor parallelism" we're talking about splitting these multi-dimensional arrays across GPUs.
How Tensor Parallelism Actually Works
Here's what happens when you split a single transformer layer across 4 GPUs.
The Attention Mechanism Split
In a transformer, the attention mechanism computes Query, Key, and Value matrices:
Input: [batch_size, sequence_length, hidden_size]
Example: [1, 1024, 4096]
Weight matrices:
W_Q: [4096, 4096] # Query projection
W_K: [4096, 4096] # Key projection
W_V: [4096, 4096] # Value projection
Without tensor parallelism (single GPU):
Q = Input @ W_Q # Matrix multiply on one GPU
K = Input @ W_K
V = Input @ W_V
With tensor parallelism across 4 GPUs:
The weight matrices are split column-wise across GPUs:
GPU 0: W_Q[:, 0:1024], W_K[:, 0:1024], W_V[:, 0:1024]
GPU 1: W_Q[:, 1024:2048], W_K[:, 1024:2048], W_V[:, 1024:2048]
GPU 2: W_Q[:, 2048:3072], W_K[:, 2048:3072], W_V[:, 2048:3072]
GPU 3: W_Q[:, 3072:4096], W_K[:, 3072:4096], W_V[:, 3072:4096]
Each GPU computes its slice:
GPU 0: Q_0 = Input @ W_Q[:, 0:1024] # Output shape: [1, 1024, 1024]
GPU 1: Q_1 = Input @ W_Q[:, 1024:2048] # Output shape: [1, 1024, 1024]
GPU 2: Q_2 = Input @ W_Q[:, 2048:3072] # Output shape: [1, 1024, 1024]
GPU 3: Q_3 = Input @ W_Q[:, 3072:4096] # Output shape: [1, 1024, 1024]
Then they concatenate the results:
Q = concatenate([Q_0, Q_1, Q_2, Q_3], dim=-1) # Shape: [1, 1024, 4096]
But here's the problem: all GPUs need the full Input tensor to do their computation. So the input must be broadcast to all GPUs. And the concatenation requires an all-gather operation across GPUs.
Multi-Head Attention: Head Parallelism
Transformers use multi-head attention. For example, Qwen3-30B has 40 attention heads.
With 4 GPUs, you can split the heads:
- GPU 0: Heads 0-9 (10 heads)
- GPU 1: Heads 10-19 (10 heads)
- GPU 2: Heads 20-29 (10 heads)
- GPU 3: Heads 30-39 (10 heads)
Each GPU computes attention independently for its heads. This is more efficient because:
- No need to split within a head
- Each head's computation is independent
- Only need to gather the final outputs
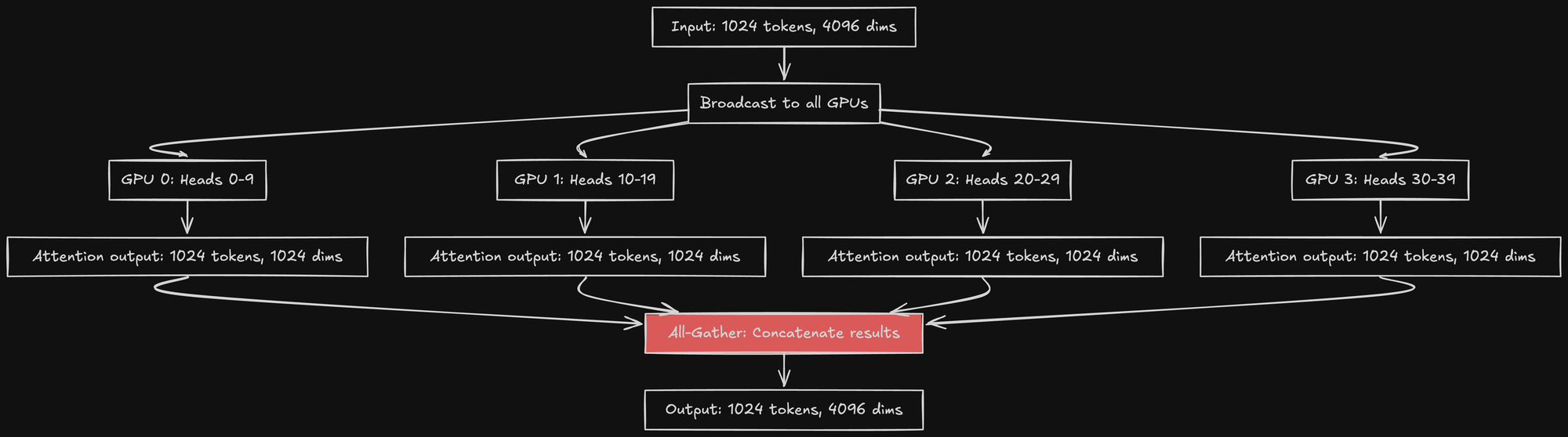
Notice the all-gather operation (in red). This requires GPU-to-GPU communication.
The Feed-Forward Network Split
After attention, there's a feed-forward network (FFN):
FFN has two layers:
1. Linear up-projection: [4096, 11008]
2. Linear down-projection: [11008, 4096]
With tensor parallelism:
GPU 0: Computes columns 0-2752 of up-projection
GPU 1: Computes columns 2752-5504
GPU 2: Computes columns 5504-8256
GPU 3: Computes columns 8256-11008
# After activation function (computed independently per GPU):
GPU 0: Computes down-projection for its slice
GPU 1: Computes down-projection for its slice
GPU 2: Computes down-projection for its slice
GPU 3: Computes down-projection for its slice
Then an all-reduce operation sums the results from all GPUs.
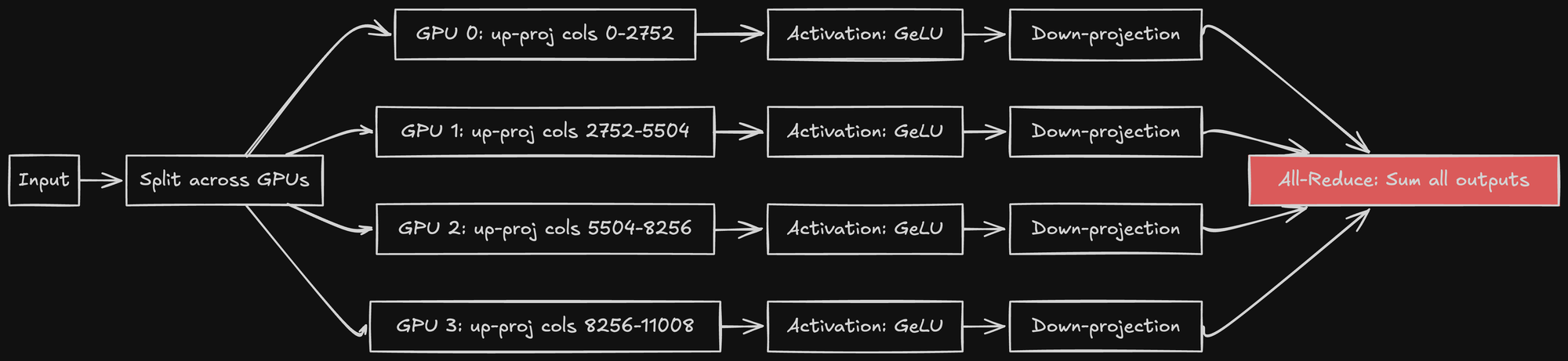
Again, the all-reduce (in red) requires expensive GPU communication.
Communication Operations Per Layer
For a single transformer layer with tensor parallelism:
- Broadcast input to all GPUs
- All-gather after QKV projection (if splitting by columns)
- All-gather after attention computation (if splitting by heads)
- All-reduce after feed-forward down-projection
That's 3-4 collective communication operations per layer.
For Qwen3-30B with 60 layers: 180-240 communication operations per forward pass.
Training vs Inference: Why Tensor Parallelism Differs
Tensor parallelism behaves differently during training vs inference.
During Training
Forward pass: Same as inference - requires all-gather and all-reduce operations.
Backward pass: Gradients must be synchronized across GPUs.
For each weight matrix split across GPUs, the gradient with respect to that weight is computed locally on each GPU. Then:
- All-reduce gradients across GPUs to sum them
- Update weights locally on each GPU
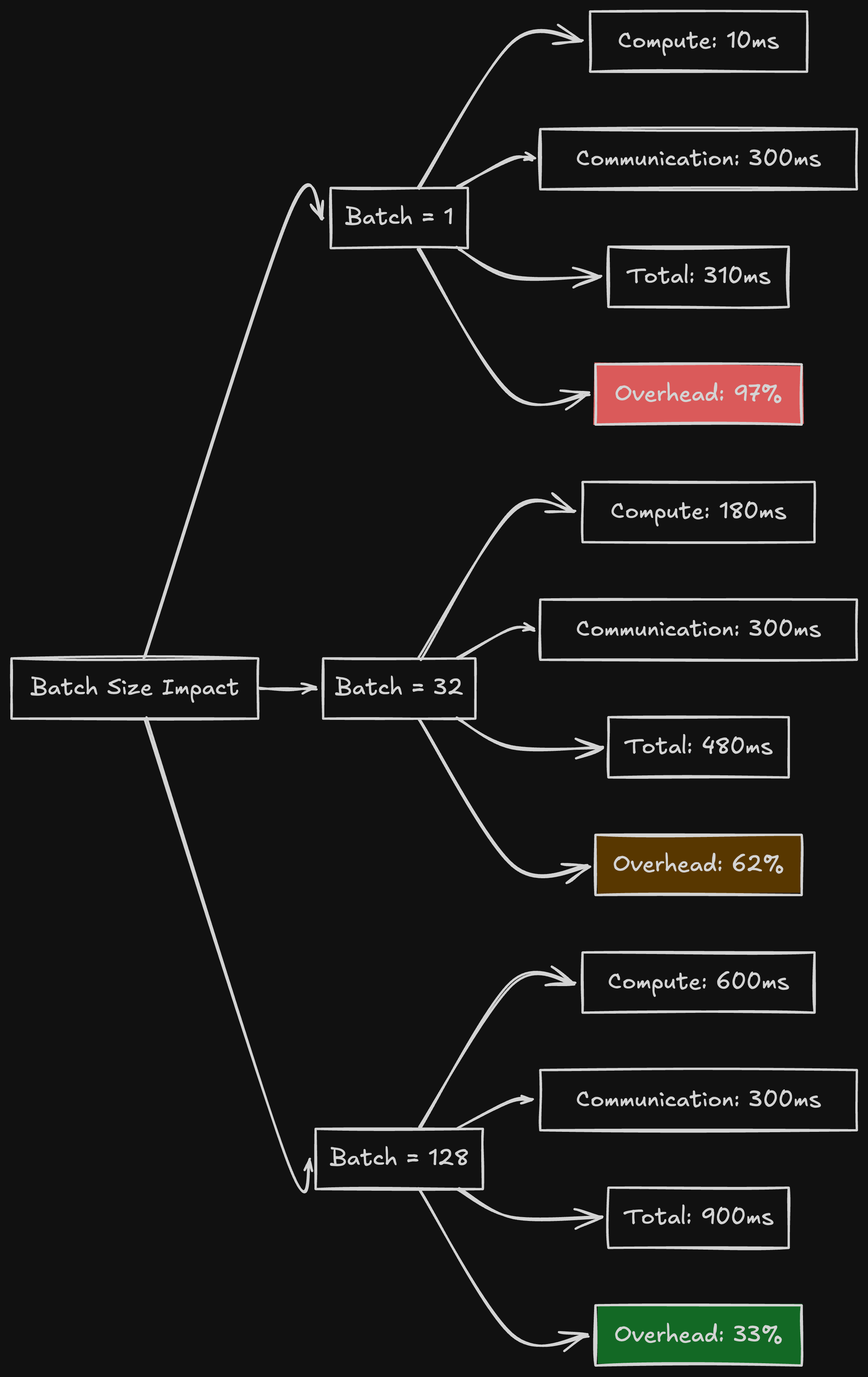
Because training uses large batches (often 128-1024 examples), the compute time dominates:
Compute time: ~500ms per layer (large batch)
Communication time: ~2ms per all-reduce
Total per layer: ~502ms
Communication overhead: 0.4%
The communication is negligible compared to compute.
During Inference
Forward pass only: No backward pass, no gradient synchronization.
But with small batches (often 1-8 examples), compute time is tiny:
Compute time: ~5ms per layer (small batch)
Communication time: ~2ms per all-reduce
Total per layer: ~7ms
Communication overhead: 28.6%
Suddenly, communication is 28% of your total time!
With batch size = 1 (single request inference):
Compute time: ~1ms per layer
Communication time: ~2ms per all-reduce
Total per layer: ~3ms
Communication overhead: 66.7%
Communication dominates compute. This is why tensor parallelism fails for low-latency inference.

Why Training Still Benefits
Even though training requires more communication (forward + backward), it benefits from tensor parallelism because:
- Large batches amortize communication cost
- Gradient accumulation allows even larger effective batch sizes
- Memory savings are critical (activations + gradients + optimizer states)
- Throughput matters more than latency in training
For inference:
- Small batches make communication expensive
- No gradients means less memory pressure
- Latency matters - every millisecond counts
- Memory is cheap - just buy a bigger GPU
Deep Dive: NCCL and Collective Communication
When GPUs communicate, they use NVIDIA's NCCL (NVIDIA Collective Communications Library). Understanding NCCL is key to understanding why tensor parallelism is slow on cloud GPUs.
What Is NCCL?
NCCL provides optimized implementations of collective communication operations:
- Broadcast: One GPU sends data to all others
- All-gather: Each GPU shares its data with all others
- All-reduce: Each GPU contributes data, result is reduced (sum/max/min) and shared with all
- Reduce-scatter: All-reduce but each GPU gets only its slice
These operations are the foundation of distributed deep learning.
The All-Reduce Algorithm: Ring-Reduce
Let's break down how all-reduce works with 4 GPUs using the ring algorithm.
Suppose each GPU has a value it wants to sum across all GPUs:
GPU 0: [1, 2, 3, 4]
GPU 1: [5, 6, 7, 8]
GPU 2: [9, 10, 11, 12]
GPU 3: [13, 14, 15, 16]
Goal: Each GPU should end up with [28, 32, 36, 40]
(sum of all corresponding elements)
Phase 1: Reduce-Scatter (N-1 steps, where N=4 GPUs)
GPUs arranged in a ring: GPU 0 → GPU 1 → GPU 2 → GPU 3 → GPU 0
Each GPU's data is divided into 4 chunks.
Step 1:
GPU 0 sends chunk 0 to GPU 1
GPU 1 sends chunk 1 to GPU 2
GPU 2 sends chunk 2 to GPU 3
GPU 3 sends chunk 3 to GPU 0
After receiving and summing:
GPU 0: [1+13, 2, 3, 4]
GPU 1: [5, 6+1, 7, 8]
GPU 2: [9, 10, 11+5, 12]
GPU 3: [13, 14, 15, 16+9]
Step 2:
GPU 0 sends updated chunk 3 to GPU 1
GPU 1 sends updated chunk 0 to GPU 2
GPU 2 sends updated chunk 1 to GPU 3
GPU 3 sends updated chunk 2 to GPU 0
After receiving and summing:
GPU 0: [1+13, 2, 3+11+5, 4]
GPU 1: [5+6+1, 6+1, 7, 8+16+9]
GPU 2: [9, 10+15, 11+5, 12]
GPU 3: [13, 14, 15+7, 16+9]
Continue for N-1 = 3 steps total.
After reduce-scatter, each GPU has the complete sum for 1/4 of the data.
Phase 2: All-Gather (N-1 steps)
Now each GPU shares its fully-reduced chunk with others.
Step 1:
GPU 0 sends its complete chunk 3 to GPU 1
GPU 1 sends its complete chunk 0 to GPU 2
GPU 2 sends its complete chunk 1 to GPU 3
GPU 3 sends its complete chunk 2 to GPU 0
Continue for N-1 = 3 steps.
After all-gather, all GPUs have the complete result: [28, 32, 36, 40].
Total communication:
- Each GPU sends N-1 messages in reduce-scatter
- Each GPU sends N-1 messages in all-gather
- Total: 2(N-1) messages per GPU
- For 4 GPUs: 6 messages per GPU
Data transferred per GPU:
If total data size is S, each message is S/N in size.
Total per GPU: 2(N-1) × S/N = 2S(N-1)/N
For large N, this approaches 2S. Very efficient!
Ring vs Tree Algorithms
NCCL supports multiple algorithms:
Ring Algorithm:
- Best for bandwidth optimization
- All GPUs participate equally
- Latency: O(N) - depends on number of GPUs
- Bandwidth: O(1) - optimal use of links
Tree Algorithm:
- Best for latency optimization
- GPUs arranged in a binary tree
- Latency: O(log N) - much faster for many GPUs
- Bandwidth: O(log N) - less efficient
NCCL automatically chooses based on message size and topology.
For small messages (< 1MB): Tree algorithm (lower latency)
For large messages (> 1MB): Ring algorithm (higher bandwidth)
Network Topology Matters
NCCL's performance depends heavily on how GPUs are connected.
Best: NVLink (GPU-to-GPU direct connection)
[GPU 0] ←→ [GPU 1]
↕ ↕
[GPU 2] ←→ [GPU 3]
- Bandwidth: 900 GB/s (NVLink 4.0 on H200)
- Latency: ~2 µs
- Protocol: GPU-Direct (no CPU involvement)
Okay: PCIe within same NUMA node
[CPU/NUMA Node]
│
───────┴───────
│ │ │
[GPU 0][GPU 1][GPU 2]
- Bandwidth: 64 GB/s (PCIe 4.0 x16)
- Latency: ~20 µs
- Protocol: PCIe transfers through CPU
Bad: PCIe across NUMA nodes
[CPU/NUMA 0] [CPU/NUMA 1]
│ │
[GPU 0] [GPU 1]
- Bandwidth: 32 GB/s (halved due to NUMA boundary)
- Latency: ~40 µs
- Protocol: PCIe + inter-socket communication
Worst: TCP/IP across machines
[Machine 0] ←→ [Machine 1]
[GPU 0] TCP [GPU 1]
- Bandwidth: 10-100 Gb/s (1.25-12.5 GB/s for 10-100 GbE)
- Latency: ~50-200 µs
- Protocol: TCP/IP network stack
What I Saw in NCCL Logs
When I enabled NCCL debugging:
export NCCL_DEBUG=INFO
export NCCL_DEBUG_SUBSYS=ALL
I saw this in the logs:
NCCL INFO [send] via NET/Socket
This means: TCP sockets. The slowest possible mode.
Why? Because the H200 GPUs in DigitalOcean weren't connected via NVLink. They were separate instances, communicating over the network.
What I wanted to see:
NCCL INFO [send] via P2P/IPC
This would mean: Peer-to-peer over NVLink or fast PCIe, orders of magnitude faster.
Or for cross-machine with InfiniBand:
NCCL INFO [send] via NET/IB/GDRDMA
This would mean: GPU-Direct RDMA over InfiniBand, which bypasses the CPU and is much faster than TCP.
But cloud providers don't give you NVLink or InfiniBand. You get PCIe at best, TCP sockets at worst.
Understanding Tensor Parallelism vs Pipeline Parallelism
There are two main ways to split a model across GPUs:

Tensor Parallelism:
- Each layer is split across multiple GPUs
- GPU 0 has the first 25% of each weight matrix
- GPU 1 has the next 25%, and so on
- All GPUs must synchronize after every layer
Pipeline Parallelism:
- Each GPU holds complete layers
- GPU 0 has layers 1-10
- GPU 1 has layers 11-20, etc.
- GPUs pass activations sequentially
For inference with small batch sizes, pipeline parallelism seems better (less communication). But vLLM uses tensor parallelism by default. Why?
Because pipeline parallelism has bubble time: while GPU 0 is processing token 5, GPUs 1-3 are idle waiting for the activation. For single-request inference, you can't fill the pipeline efficiently.
Tensor parallelism keeps all GPUs busy, but at a cost: communication overhead.
The Memory Math: Do I Even Need Multi-GPU?
My model: Qwen3-30B
- Weights: ~60GB FP16
- KV cache at 60k context: ~55GB
- Total: ~115GB
Single H200 GPU:
- VRAM: 141GB
- With 0.75 utilization: 106GB usable
Wait. The model already fits on one GPU. Why am I even considering tensor parallelism?
Because I thought splitting across GPUs would let me serve more requests simultaneously. More memory = bigger batch size = higher throughput.
This was my first mistake.
Experiment: Tensor Parallel Size = 4
I configured vLLM to split the model across 4 H200 GPUs:
model: Qwen/Qwen3-30B-A3B-Instruct-2507
tensor-parallel-size: 4
max-model-len: 8192
gpu-memory-utilization: 0.9
max-num-seqs: 512
Key changes:
tensor-parallel-size: 4instead of1- Requested 4 GPUs instead of 1
- Increased max-num-seqs from 128 to 512 (hoping for higher throughput)
- Reduced context window to 8192 (was 60k)
The Hardware Setup
I was initially on AWS g5.24xlarge instances:
- 4x NVIDIA A10G GPUs (24GB VRAM each)
- GPUs connected via PCIe 4.0
- No NVLink
Later, I switched to DigitalOcean H200 GPU nodes:
- 1x NVIDIA H200 GPU (141GB VRAM)
- But I wanted to test multi-GPU, so I spun up a 4-GPU setup
The H200s weren't connected via NVLink in the cloud setup. They communicated over PCIe 4.0, just like the A10Gs.
This matters. A lot.
Understanding GPU Interconnects
When GPUs need to communicate (and with tensor parallelism, they communicate constantly), the interconnect bandwidth determines performance.
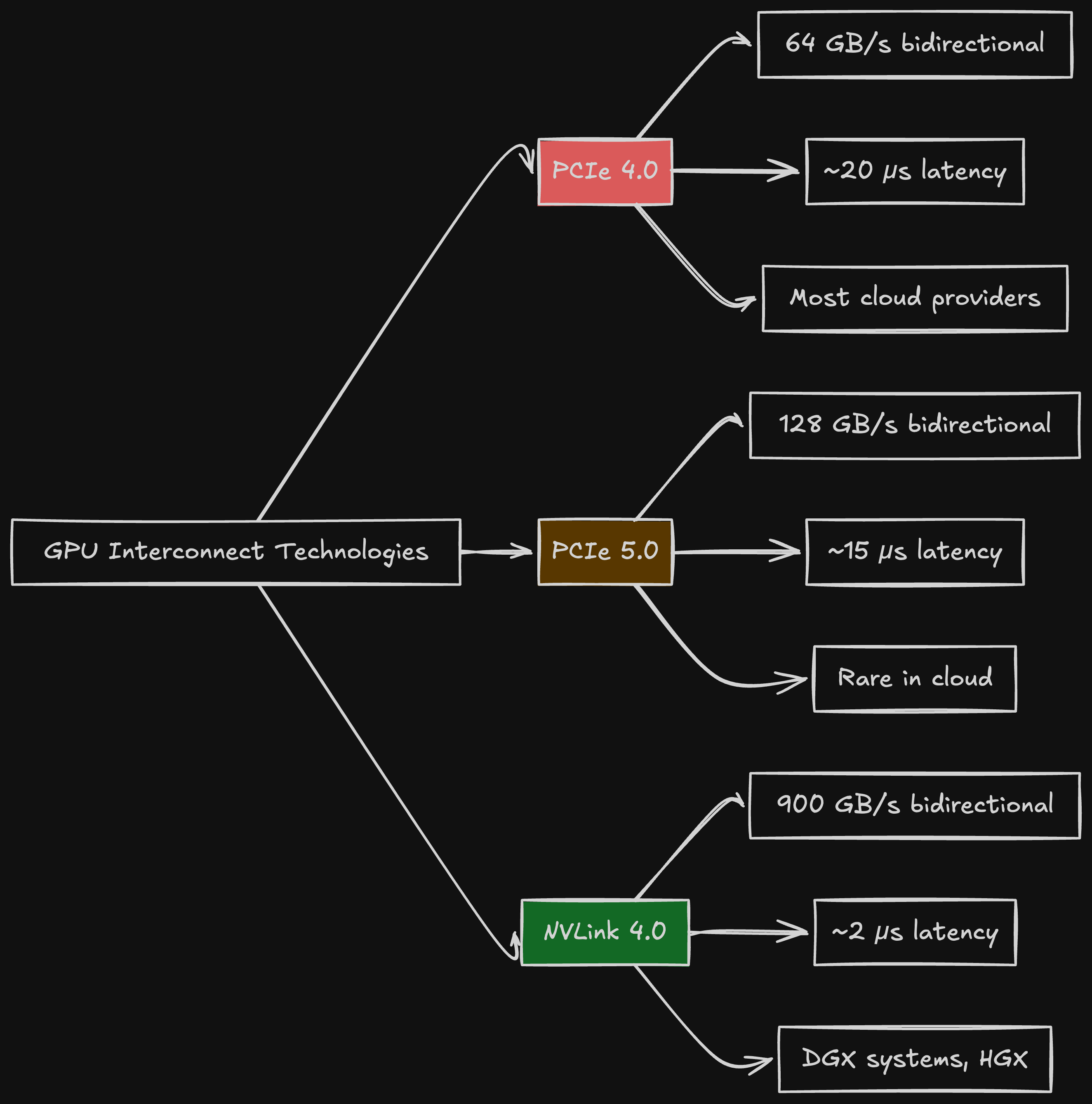
PCIe 4.0: 64 GB/s
NVLink 4.0 (H200): 900 GB/s
That's a 14x difference in bandwidth.
For tensor parallelism, every layer requires an all-reduce operation to synchronize gradients across GPUs. With PCIe, this is slow. With NVLink, it's fast.
Cloud providers rarely give you NVLink. You get PCIe.
The NCCL Communication Overhead
vLLM uses NVIDIA's NCCL (NVIDIA Collective Communications Library) for GPU-to-GPU communication in tensor parallelism.
I enabled NCCL debug logging to see what was happening:
env:
- name: NCCL_DEBUG
value: INFO
- name: NCCL_DEBUG_SUBSYS
value: ALL
In the logs, I saw:
[send] via NET/Socket
This means NCCL is using raw TCP sockets for cross-GPU communication. Not even RDMA. This is the slowest possible mode.
What I wanted to see:
[send] via NET/IB/GDRDMA
That would mean InfiniBand with GPU-Direct RDMA, which is efficient for cross-node communication.
Or better yet, for single-node multi-GPU:
[send] via P2P/IPC
Which means direct GPU-to-GPU memory access over NVLink or fast PCIe.
But I was getting NET/Socket. Because the cloud GPUs weren't configured with proper interconnects.
Benchmarking: Single GPU vs 4 GPUs
I ran the same workload on both configurations and measured:
- Time to first token (TTFT)
- Inter-token latency
- Throughput (requests per second)
Test Setup
- 100 concurrent requests
- Each request: 1000 token prompt, 500 token generation
- Structured output using Outlines (JSON schema constraints)
Results: Single GPU (Baseline)
Configuration: tensor-parallel-size=1, max-model-len=60000
TTFT: 450ms (p50), 680ms (p95)
Inter-token latency: 22ms (p50), 35ms (p95)
Throughput: 12.4 requests/second
GPU utilization: 85-90%
Results: 4 GPUs (Tensor Parallelism)
Configuration: tensor-parallel-size=4, max-model-len=8192
TTFT: 1250ms (p50), 1900ms (p95)
Inter-token latency: 68ms (p50), 105ms (p95)
Throughput: 8.1 requests/second
GPU utilization per GPU: 40-50%
Wait. The 4-GPU setup was slower?
- TTFT: 2.8x worse (1250ms vs 450ms)
- Inter-token latency: 3.1x worse (68ms vs 22ms)
- Throughput: 35% lower (8.1 vs 12.4 req/s)
How is this possible?
Why Tensor Parallelism Failed
1. Communication Overhead Dominates
With tensor parallelism, every transformer layer requires communication:
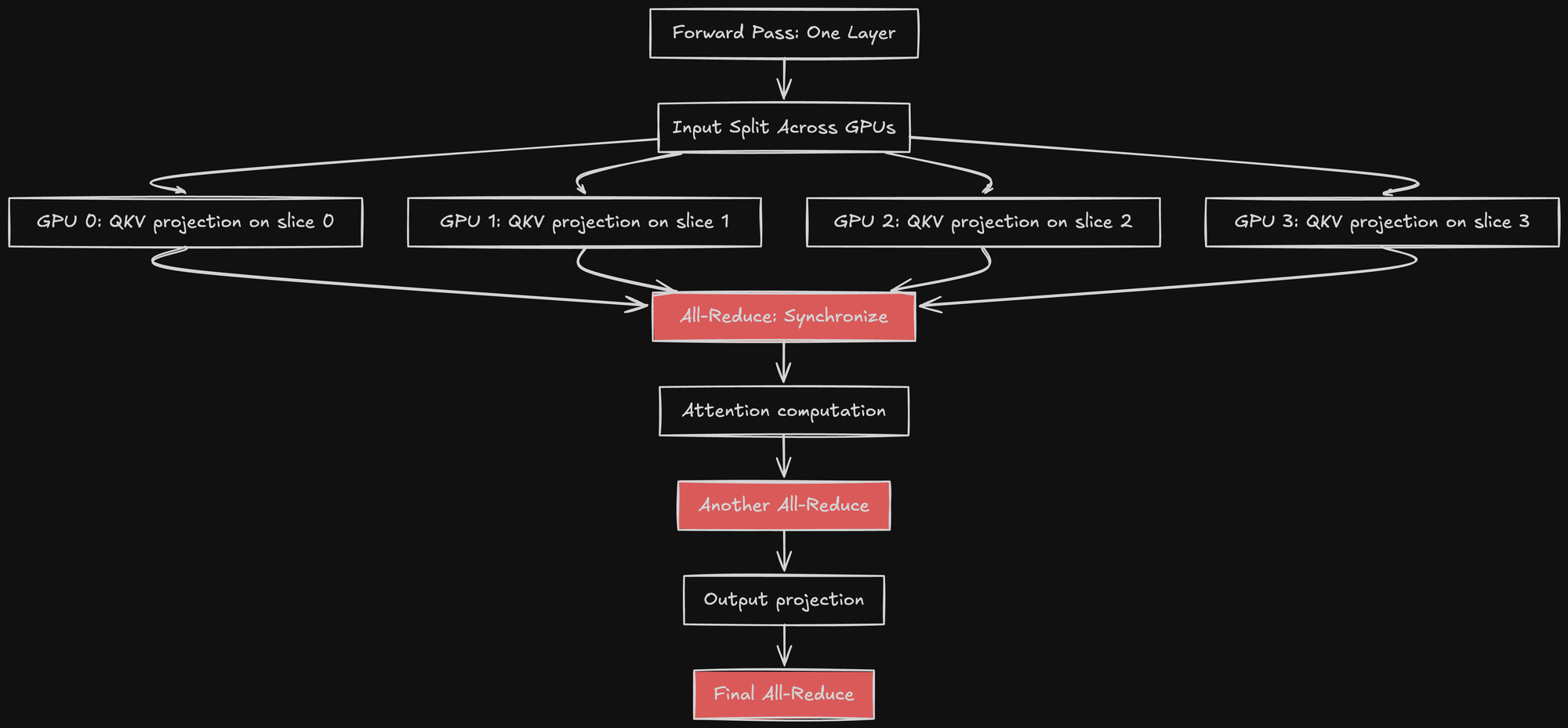
For a 30B model with ~60 layers, that's:
- 3 all-reduce operations per layer
- 180 all-reduce operations per forward pass
- Each all-reduce with 4 GPUs over PCIe: ~1-2ms
Total communication overhead: 180-360ms per forward pass.
On a single GPU, there's no communication. It's just compute.
2. Small Batch Size
Tensor parallelism amortizes communication overhead over batch size:
- Large batch: compute time dominates, communication is a smaller percentage
- Small batch: communication time dominates, compute is tiny
For structured output generation, I can't use huge batches. Each request has different JSON schemas, different prompt lengths, and different generation lengths. Batching is limited to maybe 8-16 similar requests.
With small batches, tensor parallelism overhead kills you.
3. Memory Isn't the Bottleneck
I thought 4 GPUs = 4x memory = 4x throughput.
But throughput isn't limited by memory. It's limited by compute and communication.
With tensor parallelism:
- Each GPU holds 1/4 of the model (15GB)
- But KV cache is replicated across all GPUs
- So memory savings aren't 4x
The KV cache is duplicated because each GPU needs the full context to compute attention. You only split the model weights, not the KV cache.
Memory per GPU with tensor-parallel-size=4:
- Model weights: 60GB / 4 = 15GB
- KV cache: 40GB (NOT divided by 4)
- Total: 55GB per GPU
Memory on single GPU:
- Model weights: 60GB
- KV cache: 40GB
- Total: 100GB
I'm only saving 45GB by using 4 GPUs instead of 1. That's not enough to justify the communication overhead.
4. Reduced Context Window
To make the 4-GPU setup fit in memory, I had to reduce the context window from 60k to 8k tokens.
This directly hurt structured output quality. Remember from the previous article: longer context windows allow for:
- More detailed system prompts
- More few-shot examples
- Larger input documents
Cutting context from 60k to 8k meant worse quality for the same throughput.
The Breaking Point: AWS g5.24xlarge
The g5.24xlarge has 4x A10G GPUs (24GB each).
I initially tried to run Qwen3-30B with tensor parallelism on this instance. The memory math:
- Model weights split across 4 GPUs: 60GB / 4 = 15GB per GPU (fits in 24GB)
- KV cache replicated: 40GB per GPU (doesn't fit in 24GB)
I had to:
- Reduce context window to 4096 tokens (KV cache drops to ~10GB)
- Reduce max-num-seqs to 64
- Use aggressive memory utilization (0.95)
Even then, I hit OOM errors under load.
The problem: with tensor parallelism, all GPUs must have enough memory for the full KV cache of all concurrent requests.
If I want to serve 64 concurrent requests with 4k context each:
- KV cache per request: ~2.5GB
- Total KV cache: 64 x 2.5GB = 160GB
- Per GPU: 160GB (not divided)
This doesn't fit in 24GB per GPU, even with the model split.
When Tensor Parallelism Works
I'm not saying tensor parallelism is useless. It works well when:
1. NVLink or InfiniBand Interconnects
On DGX systems with NVLink, communication is 14x faster. The overhead becomes manageable.
Example: DGX H100 with 8 GPUs connected via NVLink
- All-reduce latency: ~0.1ms (vs 1-2ms on PCIe)
- Total communication overhead: 18ms (vs 180-360ms)
At that point, tensor parallelism makes sense.
2. Large Batch Sizes
If you can batch 128+ requests together, communication overhead is amortized:
- Compute time dominates (600ms+)
- Communication time becomes small percentage (300ms)
But for structured output with diverse schemas, large batches are rare.
3. Models That Don't Fit on One GPU
If your model is 405B parameters (810GB in FP16), you have no choice. You need tensor parallelism.
But for a 30B model on H200 (141GB VRAM), it's unnecessary.
4. Throughput Over Latency
If you care about requests per second over per-request latency, tensor parallelism with large batches can help.
But I care about p50 and p95 latency. Users don't care about throughput; they care about response time.
Alternative: Increase Replicas Instead
Instead of 1 instance with 4 GPUs, what about 4 instances with 1 GPU each?
This is called data parallelism or model replicas.

With 4 replicas:
- Each instance handles 12.4 req/s
- Total throughput: 49.6 req/s
- No communication overhead
- Better fault tolerance (one instance down = 75% capacity remaining)
With tensor parallelism on 4 GPUs:
- One instance handles 8.1 req/s
- Total throughput: 8.1 req/s
- Communication overhead dominates
- No fault tolerance (one GPU fails = entire instance down)
Model replicas are strictly better for my use case.
The Cost Analysis
Let's compare costs:
Option A: Tensor Parallelism (4 GPUs on one instance)
DigitalOcean H200 4-GPU instance:
- Cost: ~$10,000/month
- Throughput: 8.1 req/s
- Latency p50: 1250ms
Cost per 1000 requests: $10,000 / (8.1 req/s x 86400s x 30d) x 1000 = $0.047
Option B: Single GPU Replicas (4 separate instances)
DigitalOcean H200 1-GPU instance:
- Cost: $2,622/month per instance
- 4 instances: $10,488/month
- Throughput per instance: 12.4 req/s
- Total throughput: 49.6 req/s
- Latency p50: 450ms
Cost per 1000 requests: $10,488 / (49.6 req/s x 86400s x 30d) x 1000 = $0.008
Option B is:
- 6x cheaper per request
- 2.8x lower latency
- Better fault tolerance
The choice is obvious.
GPU Utilization: A Misleading Metric
When I looked at GPU utilization with tensor parallelism, each GPU showed 40-50%.
I initially thought: "The GPUs are underutilized! I need to increase batch size!"
But that's the wrong interpretation. The GPUs were idle waiting for communication, not idle waiting for work.
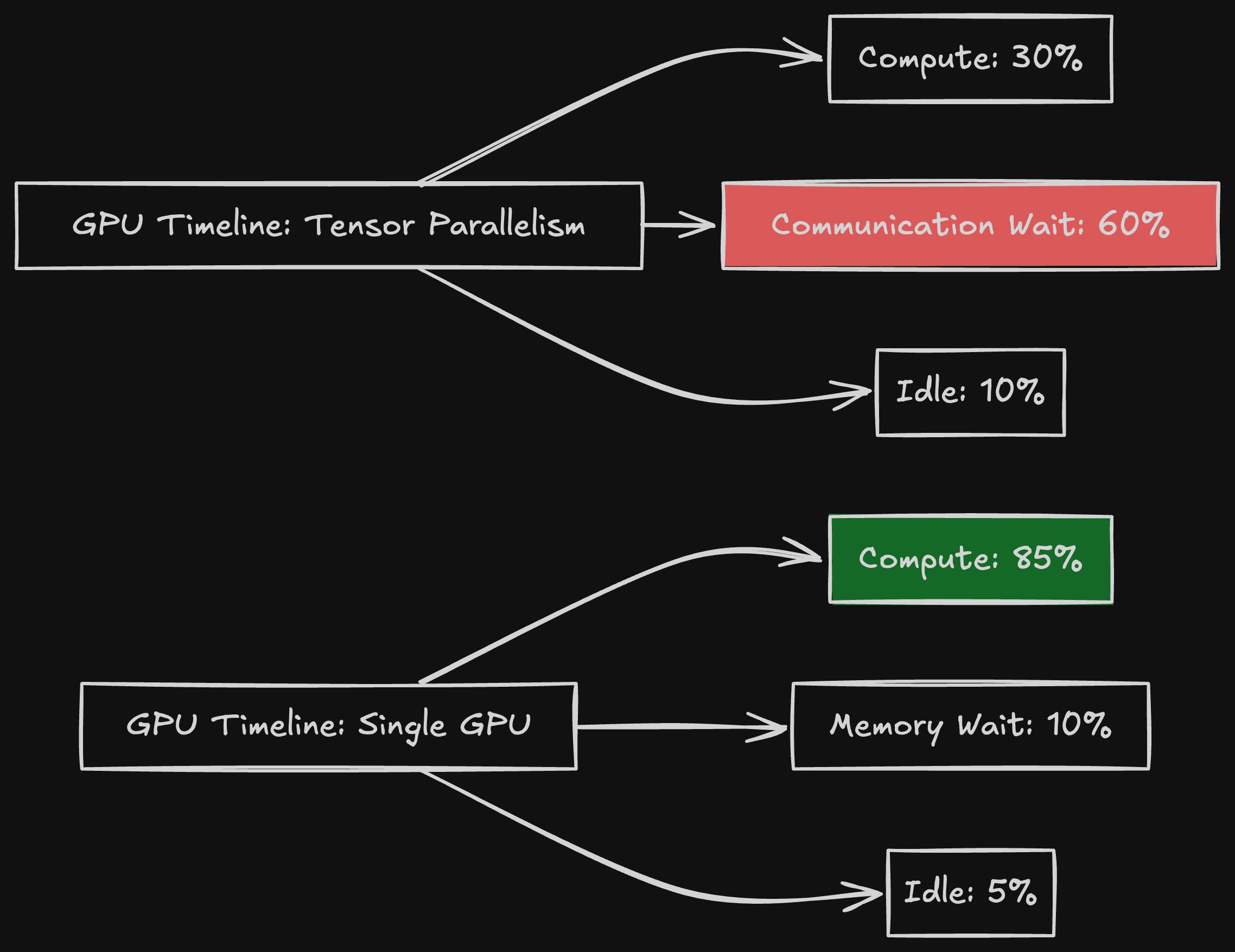
Low GPU utilization in tensor parallelism doesn't mean you need more load. It means your GPUs are communication-bound.
Pipeline Parallelism: The Road Not Taken
I briefly considered pipeline parallelism as an alternative:
- Split layers across GPUs instead of splitting each layer
- GPU 0: Layers 1-15
- GPU 1: Layers 16-30
- GPU 2: Layers 31-45
- GPU 3: Layers 46-60
This reduces communication (only pass activations between layers, not within layers).
But pipeline parallelism has bubble time: when GPU 0 is processing request 2, GPUs 1-3 are idle waiting.
For single-request inference (common in structured output), pipeline parallelism is even worse than tensor parallelism.
Pipeline parallelism works for training with large batches and micro-batching. Not for low-latency inference.
The Final Configuration: Single H200 GPU
After all the experiments, I went back to the simplest configuration:
model: Qwen/Qwen3-30B-A3B-Instruct-2507
tensor-parallel-size: 1
max-model-len: 60000
gpu-memory-utilization: 0.75
max-num-seqs: 128
enable-chunked-prefill: true
enforce-eager: true
resources:
requests:
nvidia.com/gpu: "1"
Single GPU. No parallelism. Simple.
This gave me:
- Best latency (450ms TTFT)
- Largest context window (60k tokens)
- Simplest deployment
- Lowest cost per request
When I need more throughput, I add replicas. Not GPUs per instance.
Lessons Learned
1. Communication Overhead Is Real
Tensor parallelism sounds great in theory. In practice, GPUs spend more time synchronizing than computing when interconnects are slow.
PCIe 4.0 is not fast enough for efficient tensor parallelism. You need NVLink or InfiniBand.
2. Cloud GPUs Lack NVLink
Most cloud providers (AWS, GCP, Azure, DigitalOcean) give you PCIe-connected GPUs, not NVLink.
DGX systems with NVLink exist, but they're expensive and rare.
For cloud inference, assume PCIe interconnects.
3. Small Batches Kill Tensor Parallelism
Communication overhead is amortized over batch size. With batch=1 or batch=8, tensor parallelism is pure overhead.
Structured output generation has small, variable-sized batches. Tensor parallelism is a bad fit.
4. Model Replicas > Tensor Parallelism
For throughput scaling, horizontal scaling (more instances) beats tensor parallelism (more GPUs per instance).
Unless your model doesn't fit on one GPU, don't use tensor parallelism.
5. Memory Isn't Always the Bottleneck
I thought 4 GPUs = 4x memory = 4x throughput. Wrong.
KV cache is replicated across GPUs in tensor parallelism. You don't get 4x memory.
And even if you did, throughput is limited by compute and communication, not memory.
6. Simpler Is Better
Single GPU, single model instance, simple deployment. Scale by adding replicas.
This is easier to manage, easier to debug, and more cost-effective than complex multi-GPU setups.
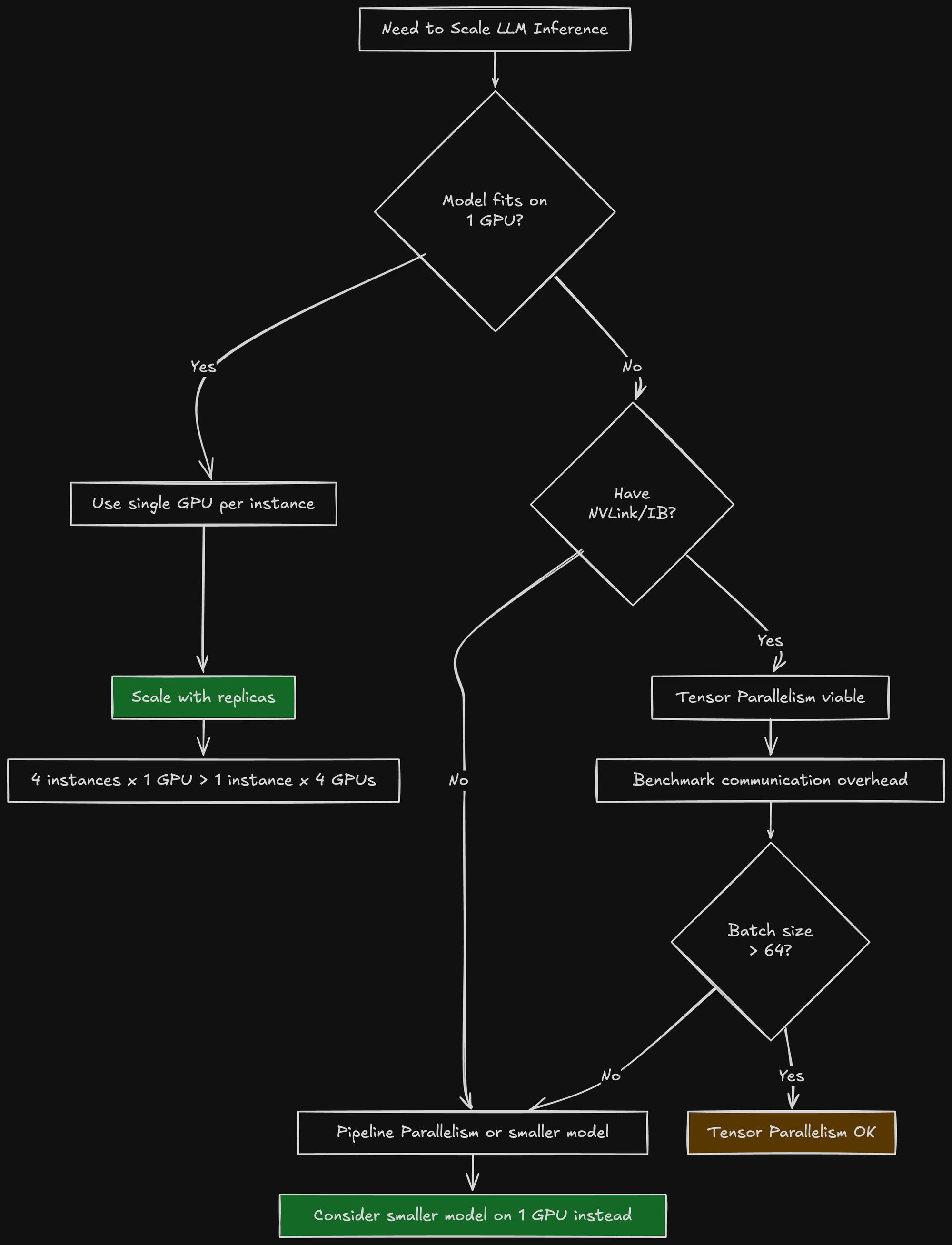
The Decision Tree for Parallelism
Here's how I think about parallelism now:
When I Would Use Tensor Parallelism
Despite all the negatives, tensor parallelism has its place:
- Model > GPU VRAM: 405B model on H200? You need 3+ GPUs minimum.
- NVLink available: DGX systems make tensor parallelism fast.
- Large, uniform batches: Batch size 128+ with similar request lengths.
- Throughput > latency: You optimize for requests/second, not milliseconds per request.
But for structured output on cloud GPUs with a 30B model? Tensor parallelism is the wrong tool.
What's Next
In the next article, I'll dive into KV cache optimization. I experimented with:
- Increasing context window from 16k to 60k tokens
- Chunked prefill for long prompts
- Prefix caching for repeated prompts
- Memory profiling to understand KV cache growth
The KV cache turned out to be the biggest consumer of GPU memory, and optimizing it made a bigger difference than any multi-GPU setup.
Stay tuned for "KV Cache: The Hidden Memory Monster in LLM Inference."
TL;DR: I tried splitting Qwen3-30B across 4 GPUs using tensor parallelism to increase throughput. It was 2.8x slower than single GPU due to communication overhead over PCIe 4.0. Without NVLink, tensor parallelism adds massive latency from all-reduce synchronization every layer. For small batch sizes (typical in structured output), communication dominates compute. Learned that scaling via model replicas (4 instances x 1 GPU) is 6x more cost-effective and 2.8x lower latency than tensor parallelism (1 instance x 4 GPUs). Unless your model doesn't fit on one GPU or you have NVLink, don't use tensor parallelism.